
Research Topics
The overall goal of my research is to provide practical, automatic techniques and tools that can improve the effectiveness and efficiency of software development and maintenance. In particular, my research to date has employed research areas of program-analysis-based software engineering, testing, machine learning, and information visualization to aid in the processes of testing and debugging.
My research addresses the problems of software debugging and maintenance. Software developers commonly face difficulties in understanding, diagnosing, and fixing bugs in software. Whereas many software-engineering researchers typically attempt to create techniques to provide fully automatic identification and location of bugs, my approach to such research takes a different tack: My research addresses the large class of bugs that are caused by logical inconsistencies — an incongruence between the developers’ expectation of how the program should behave and the way it actually does. Such common logical inconsistencies typically require developer attention and comprehension, and usually are not amenable to fully algorithmic location and repair.
As such, my goal is to assist software developers performing software maintenance and debugging tasks by facilitating their comprehension of the software and its behavior. In my research, I place a strong emphasis on practicality and efficiency — preferring potential real-world impact over expensive technical wizardry or inflexible, prescriptive workflow. I work to enable efficient and effective software engineering by assisting developers and researchers in their cognition of software behavior, with the ultimate goal of equipping them to produce higher quality software, more economically, and with less frustration.
Fundamentally, the challenges of software maintenance and debugging are primarily challenges of human comprehension, e.g., understanding:
- where the bugs reside in the codebase,
- why the code behaves incorrectly,
- who are the developers best equipped to understand and fix problems, and
- when were the changes made that introduced bugs (and why were they).
To answer such questions, we study the following research topics.
Fault Comprehension
One of the most difficult tasks in debugging software for a developer is to understand the nature of the fault. Techniques have been proposed by researchers that can help locate the fault, but mostly neglected is a way to describe the nature of the fault. We are developing software models, visualizations, and techniques to aid in the diagnosis of the faults in the software.
Publications:- P41. Revealing Runtime Features and Constituent Behaviors within Software
- P35. Visualizing Constituent Behaviors within Executions
- P32. Concept-Based Failure Clustering
- P31. Semantic Fault Diagnosis: Automatic Natural-Language Fault Descriptions
- P29. Weighted System Dependence Graph
- P26. Inferred Dependence Coverage to Support Fault Contextualization
- P24. Constellation Visualization: Augmenting Program Dependence with Dynamic Information
Software History Mining
In addition to the dynamic nature of software while executing, this dynamism extends to the evolution of the software’s code itself. The software’s evolution is often captured in its entirety by revision-control systems (such as CVS, Subversion, and Git). By utilizing this rich artifact, as well as other historical artifacts (e.g., bug-tracking systems and mailing lists), we can offer a number of techniques for recommending future actions to developers. We have developed techniques that utilize these artifacts to enable developers to view selected code lineage and suggest developer assignments for future and present development tasks.
Publications:
Software Fault Analysis
In order to produce effective fault-localization, debugging, failure-clustering, and test-suite maintenance techniques, researchers would benefit from a deeper understanding of how faults (i.e., bugs) behave and interact with each other. Some faults, even if executed, may or may not propagate to the output, and even still may or may not influence the output in a way to cause failure. Furthermore, in the presence of multiple faults, faults may interact in a way to obscure each other or in a way to produce behavior not seen in their isolation. We have investigated the nature of faults and their behavior.
Publications:- P41. Revealing Runtime Features and Constituent Behaviors within Software
- P37. Fault Density, Fault Types, and Spectra-based Fault Localization
- P35. Visualizing Constituent Behaviors within Executions
- P28. Software Behavior and Failure Clustering: An Empirical Study of Fault Causality
- P26. Inferred Dependence Coverage to Support Fault Contextualization
- P23. Fault Interaction and its Repercussions
- P21. On the Influence of Multiple Faults on Coverage-Based Fault Localization
- P17. Lightweight Fault-Localization Using Multiple Coverage Types
- P15. An Empirical Study of the Effects of Test-Suite Reduction on Fault Localization
Collaboration for Software Development and Maintenance
One of the many challenges of software development and maintenance is the need to collaborate among many constituents and stakeholders. For example, clients interact with software development organizations; software-development organizations consist of many developers and maintainers within the same location and across different locations; and the development organization often outsources some of the testing efforts to independent test agencies. Each of these parties may reside in different locations, often across many very disparate time zones. And, due to intellectual property constraints, they often cannot share all code and information. We have investigated this aspect of software engineering and have developed a vision for a system that would enable these parties to interact in a way that overcomes some of the constraints.
Publications:- P45. Generating Descriptions for Screenshots to Assist Crowdsourced Testing
- P44. Fuzzy Fine-grained Code-history Analysis
- P42. Multi-objective Test Report Prioritization using Image Understanding
- P39. Test Report Prioritization to Assist Crowdsourced Testing
- P33. History Slicing: Assisting Code-Evolution Tasks
- P20. Bridging Gaps between Developers and Testers in Globally-distributed Software Development
- P19. CASI: Preventing Indirect Conflicts through a Live Visualization
- P18. Enabling and Enhancing Collaborations between Software Development Organizations and Independent Test Agencies

Failure Clustering
We developed techniques for clustering of failures. Failure-clustering techniques attempt to categorize failing test cases according to the bugs that caused them. Test cases are clustered by utilizing their execution profiles (gathered from instrumented versions of the code) as a means to encode the behavior of those executions. Such techniques can offer suggestions for duplicate submissions of bug reports. Today, bug reports that are submitted by users (or developers) are identified as duplicates of existing, already-submitted, bug reports based on the textual descriptions of the symptoms reported in the bug reports. Alternatively, the bug reports are recognized as duplicates upon finding and fixing the bug which caused one bug report, and only later when investigating other bug reports is it found that other bug reports are no longer valid — their bugs had been fixed by earlier bug-report debugging. Such erroneous duplicate identification can cause information overload (i.e., thousands of open bug reports) and bug investigations that utilize less information than could have been offered if the duplication were correctly found. The automated techniques would provide heuristic suggestions to the developer in finding similar bug reports.
Publications:- P46. An Empirical Study on Software Failure Classification with Multi-label and Problem-Transformation Techniques
- P42. Multi-objective Test Report Prioritization using Image Understanding
- P39. Test Report Prioritization to Assist Crowdsourced Testing
- P32. Concept-Based Failure Clustering
- P28. Software Behavior and Failure Clustering: An Empirical Study of Fault Causality
- P14. Semi-Automatic Fault Localization
- P13. Debugging in Parallel
Test-Suite Maintenance
Test suites often need to adapt to the software that it is intended to test. The core software changes and grows, and as such, its test suite also needs to change and grow. However, the test suites can often grow so large as to be unmaintainable. We have developed techniques to assist in the maintenance of these test suites, specifically in allowing for test-suite reduction (while preserving coverage adequacy) and test-suite prioritization.
Publications:- P42. Multi-objective Test Report Prioritization using Image Understanding
- P39. Test Report Prioritization to Assist Crowdsourced Testing
- P7. Test-Suite Reduction and Prioritization for Modified Condition/Decision Coverage
- P5. Test-Suite Reduction and Prioritization for Modified Condition/Decision Coverage
- P3. Regression Test Selection for Java Software

Software Visualization
One method of facilitating developers to understand the complex inner nature of software that we have employed is the use of information visualization. Software is often so complex that even the developers who initially created it cannot understand all of the possible runtime behaviors that it can exhibit — specifically, all of the bugs that it may contain. In order to present large code bases with innumerable characteristics and relationships of its components (e.g., instructions, variables, values, and timings) we have developed a number of novel visualizations of software.
Publications:- P47. Hierarchical Abstraction of Execution Traces for Program Comprehension
- P44. Fuzzy Fine-grained Code-history Analysis
- P41. Revealing Runtime Features and Constituent Behaviors within Software
- P35. Visualizing Constituent Behaviors within Executions
- P34. Chronos: Visualizing Slices of Source-Code History
- P33. History Slicing: Assisting Code-Evolution Tasks
- P24. Constellation Visualization: Augmenting Program Dependence with Dynamic Information
- P14. Semi-Automatic Fault Localization
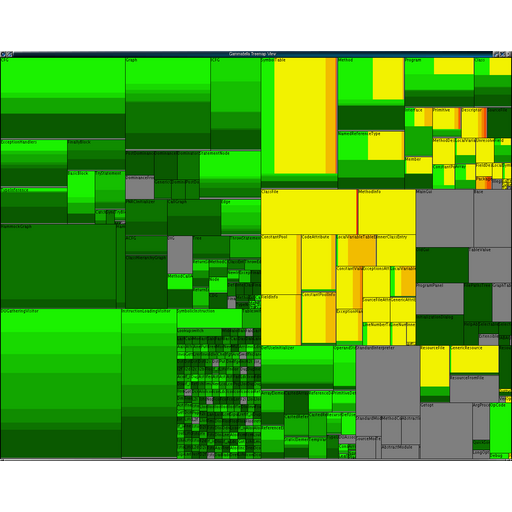
- P11. Gammatella: Visualizing Program-Execution Data for Deployed Software
- P10. Gammatella: Visualization of Program-Execution Data for Deployed Software
- P9. Fault Localization Using Visualization of Test Information
- P8. Visualization of Program-Execution Data for Deployed Software
- P6. Visualization of Test Information to Assist Fault Localization
- P4. Technical Note: Visually Encoding Program Test Information to Find Faults in Software
- P2. Visualization for Fault Localization
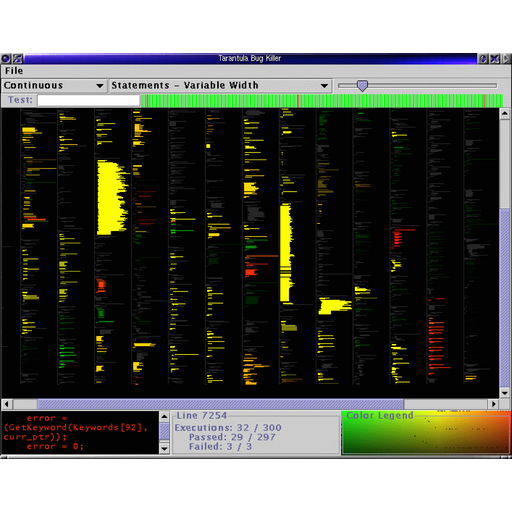
Fault Localization
We developed a fault-localization technique that utilized correlation-based heuristics. The technique and tool was called Tarantula. Tarantula uses the pass/fail statuses of test cases and the events that occurred during execution of each test case to offer the developer recommendations of what may be the faults that are causing test-case failures. The intuition of the approach is to find correlations between execution events and test-case outcomes — those events that correlate most highly with failure are suggested as places to begin investigation. These event correlations may not be causative of the failures, but they offer hints to reduce the search space of the fault. Execution event types that have been evaluated include statement execution, branch execution, data-flows, dynamic invariants, and performance profiles.
Publications:- P37. Fault Density, Fault Types, and Spectra-based Fault Localization
- P30. WhoseFault: Automatic Developer-to-Fault Assignment Through Fault Localization
- P27. Localizing SQL Faults in Database Applications
- P26. Inferred Dependence Coverage to Support Fault Contextualization
- P22. Dynamic Invariant Detection for Relational Databases
- P21. On the Influence of Multiple Faults on Coverage-Based Fault Localization
- P17. Lightweight Fault-Localization Using Multiple Coverage Types
- P16. Rapid: Identifying Bug Signatures to Support Debugging Activities
- P15. An Empirical Study of the Effects of Test-Suite Reduction on Fault Localization
- P14. Semi-Automatic Fault Localization
- P13. Debugging in Parallel
- P12. Empirical Evaluation of the Tarantula Automatic Fault-Localization Technique
- P9. Fault Localization Using Visualization of Test Information
- P6. Visualization of Test Information to Assist Fault Localization
- P4. Technical Note: Visually Encoding Program Test Information to Find Faults in Software
- P2. Visualization for Fault Localization
Program Analysis
To enable much of our research to enable program understanding, software quality, and maintenance, we utilize and develop analyses of program code. These analyses model the flows of information through the logic of programs and systems. With these analysis models enable automated techniques to assist development and maintenance tasks.
Publications:- P43. Dynamic Dependence Summaries
- P41. Revealing Runtime Features and Constituent Behaviors within Software
- P40. Spider SENSE: Software-Engineering, Networked, System Evaluation
- P38. Discriminating Influences among Instructions in a Dynamic Slice
- P36. Improving Efficiency of Dynamic Analysis with Dynamic Dependence Summaries
- P35. Visualizing Constituent Behaviors within Executions
- P29. Weighted System Dependence Graph
- P26. Inferred Dependence Coverage to Support Fault Contextualization
- P24. Constellation Visualization: Augmenting Program Dependence with Dynamic Information
- P22. Dynamic Invariant Detection for Relational Databases
- P3. Regression Test Selection for Java Software
- P1. Empirical Studies of Program Dependence Graph Size for C Programs
